- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
2.0 Upgrade
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-20-2011 06:38 AM - edited 03-01-2019 10:04 AM
Has anyone completed the upgrade to 2.0? And if so, how was your experience?
I have the firmware bundles downloaded and am preparing to run the upgrade but wanted to know if anyone has run into any issues. I have checked and do not have any FCoE VLAN overlap.
- Labels:
-
Unified Computing System (UCS)
")
")
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 06:36 AM
Can you both also advise if youi're using one or two adaptors (in case of B250/B440).
Thanks,
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 06:41 AM
I have a dual adapter and yes,I have a placement policy. The ESX version is 5 if it matters, I missed that in my earlier post
-Sukesh Kumar
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 06:42 AM
Hi Robert!
Since we only have B200 M2 there is only one adapter in my case.
/Erik
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 06:44 AM
Let me fire this up in my lab and get back to you today. I'll test both blades with ESX 4 & 5.
Stay tuned.
Regards,
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 10:16 AM
Update went well in our lab (6120 with 4 chassis). Did note that the IOM's were in "Updating" Status for like 15 minutes simultaneously after FI’s rebooted. That was odd, but no interruption to chassis traffic. Other than that, went like any other code update. We are not doing any virtualization at this time, so cannot comment on that.
Will be doing our production system (6140 with 4 chassis) that is under heavy load. That will be the real test.
Craig
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 02:03 PM
In our lab after the update this critical error showed up. Appears and FCOE vlan and default VLAN have ID of 1.

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 02:31 PM
Overlapping FCOE VLAN and Ethernet VLANs no longer allowed with UCS 2.0.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 03:28 PM
So best fix for that (we are not using FCOE) would be to change FCOE vlan to and unused?
Craig
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-22-2011 04:34 PM
Changing the FCOE vlan-id will clear the overlapping issue.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-23-2011 02:53 AM
Yes, that is a best practice anyway that should have been followed pre-2.0. If you were to deploy Nexus 5ks with FCoE you would have to do the same for FCoE traffic.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-23-2011 11:56 AM
The FCoE VLAN Change was documented in the release notes:
http://www.cisco.com/en/US/docs/unified_computing/ucs/release/notes/OL_25363.html#wp226040
There was also a Software Advisory in the Release notes pertaining to this change.
http://www.cisco.com/web/software/datacenter/ucs/UCS_2_0_Software_Advisory.htm
As Jermey pointed out, your FCoE VLAN should never be used for anything other than FCoE, and does not need to exist outside of UCS.
Regards,
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-27-2011 11:23 AM
In regards to the PCI re-ordering issue we've identified two bugs.
CSCts86890 - B230-M1: PCI bus numbers change after an upgrade from 1.4 to 2.0
Description:
When the BIOS is upgraded on a B230-M1 blade from 1.4 release to 2.0 release, the PCI bus enumeration will shift by one bus number. This can potentially cause certain OS like VMWARE ESX, Windows to see the old VNIC’s and VHBA’s with new PCI address and could result in those interfaces being non operable unless the configuration is changed in the OS. In case of ESX, a workaround would be edit the esx.conf with the new PCI address and to modify the vswitch configuration.
Workaround:
At this time there are only two ways to correct the issue
1. In case of ESX, manually modifying the ESX.conf file to re-map the vmnic numbering.
2. Revert entire UCS System from 2.x -> to 1.4.x : VMware & Windows PCI ordering reverted back to original mapping and old NIC numbering restored Additional workarounds are under investigation.
CSCts96949 - PCI Device address changes after an upgrade from 1.4 to 2.0 release on VIC device
Description:
When a system is upgraded from UCS 1.4 and earlier releases, the PCI device address of existing Service Profile VNICs and VHBAs in case of VIC adapters changes. This can potentially cause certain OSes such as VMware ESX and Windows to see the old VNICs and VHBAs with new PCI addresses, which could result in those interfaces being non operable unless the configuration is changed in the OS. In the case of ESX, a workaround would be to edit the esx.conf with the new PCI address and to modify the vswitch configuration.
Workaround:
There are two current workarounds.
1. In case of vSphere, manually modifying the ESX.conf to re-map the PCI -> vmnic numbering
2. Downgrading the BIOS of the blade from 2.x -> 1.4.x
**Software patches for these two issues are currently being developed and will be made availalbe as soon as possible once they clear QA.
I will update this thread as soon as the patches have been released.
Regards,
Robert
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-28-2011 08:50 AM
On our 6104 UCS with 14 Chassis of B200 M2 Blades we ran into bug
(CSCTR74091)
http://www.cisco.com/web/software/datacenter/ucs/UCS_2_0_Software_Advisory.htm
Right after our first step the UCSM activation all the blades went into re-config and went offline (crashed the OS). Many had re-numbered NIC's.
FCoE VLAN was changed to 2 before update. There were no VLAN overlaps etc, UCS was perfect before update, 0 errors across top left of screen. After UCSM Activeate to 2.0 Code all blades has this error:
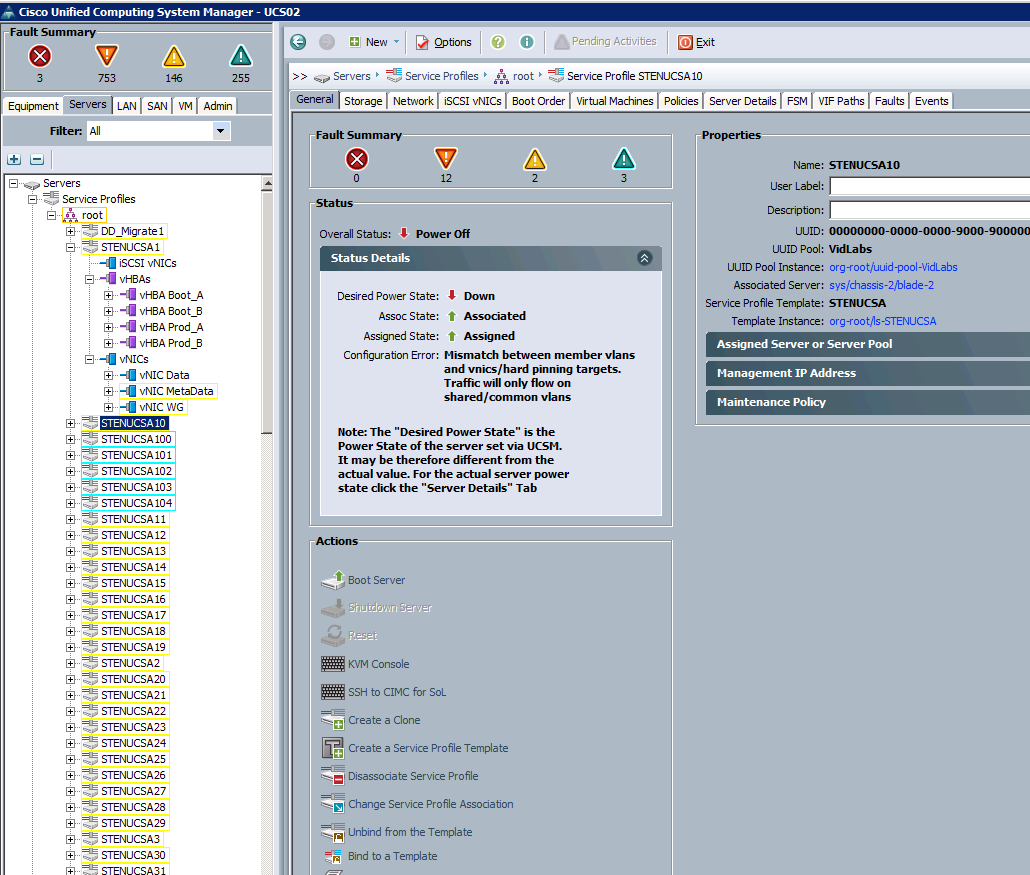
In the end we had to disassociate and associate all the service profiles to get the blades back online. These are all Windows 2008R2 machines in an Armada 4.1 encoding farm.
Also one of our vNIC pin groups will not work on failover mode after rollback. Had to switch to one fabric, and not check Enable Failover. Will work with TAC to figure that out.
TAC said a patched version of 2.0 will be out in 1 to 2 weeks that does not crash your UCS while updating. Looking forward to that.
A picture is worth a thousand words so I will summarize our 2.0 upgrade with this:

Craig
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-29-2011 03:41 PM
Would you summarize this as "completed, but not working?"

In all seriousness, thanks for the information, hopefully we can avoid our own trainwreck. Andy L found your articles/posts and shared them with us via facebook. Good stuff.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-30-2011 10:02 AM
Hi Craig, do you figured out the Pin Group Issue? i think i have the same problem, i created a Pin Group for 2 Uplinks, at service profile 1 nic is pinned to FIA and the other one is pinned to FIB, all Blades are ESXi 4.1.
I tried the Failover feature of UCS disabling one Uplink port of two in the Pin Group in this case was FIA, Mgmt traffic failover to FIB and was working, when i tried to get it back VMware detects that the first NIC is online and it tries to forward trafic to the restored Uplink but its not working, i had to disable the FIA uplink to get ESXi Management Console to get the cluster up again.
Is this kind of your scenario?
Regrads
Luis Lozano
Find answers to your questions by entering keywords or phrases in the Search bar above. New here? Use these resources to familiarize yourself with the community:

